Introduction to mathematical induction for programmers
One night I came home to my housemate Kevin just sitting at the dining table in front of our whiteboard, marker in hand, and an eager grin on his face. In the previous weeks, Kevin had been going through problems in leetcode learning about algorithms and computer science, so I had already gotten used to working through some algorithms with him.
But this night, he asked me “What do you know about … mathematical induction?”. That took me by surprise, this question seemed much too academic even compared to our usual fare. But I’m always up for playing around with formulas, so I spent some time working through some identities over the integers through induction that he had encountered recently in his studies.
Ever since then, when we would talk about algorithms as usual, I would try to point out how induction can be used to reason about every problem we discussed. Kevin, ever willing to learn by doing, would try to go through the steps he learned to apply induction:
- So I start with n = 0, since that’s the base case
- And then I assume the inductive hypothesis for n
- And show something for n + 1
- Wait a minute, we’re talking about an array, right? What does this even have to do with numbers?
This train of thought is exactly what you would get if you look up a tutorial video on mathematical induction. I remember learning about mathematic induction myself and just being confused about its application. I felt as if to be able to use mathematical induction to prove something, you would have already needed to have known that it was true in the first place!
But mathematical induction is not just a proof method for formulas by counting up the integers, it’s a way to reason about any problem that has a certain structure. And for many programming problems, it turns out that they can be reasoned about in such a way that mathematical induction gives you an algorithm that solves the problem. So in this post, I’ll be going over basic mathematical induction and some examples on how it ties back into programming and algorithms.
Reframing the typical mathematical induction introduction
Let’s first look at a typical introduction into mathematical induction. Let’s say that we have some property that may or may not hold for any natural number (i.e. is an integer that is at least 0).
The weak induction principle says that if we know that:
- holds
- and for all natural numbers . That is, if we assume already holds (this assumption is referred to as the “inductive hypothesis”), would then hold as well.
then it turns out that:
- holds for all natural numbers.
For now, let’s not worry about why the weak induction principle works. Let’s just apply it to some problem.
Problem: Prove that for any natural number
First, we check that the base case holds:
Ok, so the base case holds. Then if we assume that holds (the inductive hypothesis), we need to check that holds as well. This part is mostly just massaging some formulas until we get what we want. Here, I start from the inductive hypothesis and just add the next term (n+1) to both sides to see what happens.
So we indeed also have . Therefore, by the weak induction principle, holds for all natural numbers.
If you didn’t actually follow any of those mathematical transformations, don’t fret! I only show this to use as a typical example of mathematical induction. I think that proving mathematical identities like this is unnecessarily tricky, and can lead to someone focusing too much on mechanical manipulation of formulas.
It’s really just the structure of the underlying logic I want to highlight here. Why does this weak induction principle work at all? What does this have to do with programming?
Let’s take a step back and try to look at the general problem of proving a property for some arbitrary natural number . It might turn out because of something particular to , that if we knew something about that we could reason about . In other words, is dependent on . With similar reasoning, we could realize that is also dependent on , is also dependent on , and so on.
Even though can be arbitrarily large, is still finite (infinity is not a natural number!). That means that eventually, this chain of logic would lead to us to a for some that we may already know about, probably because it’s some trivial case. Let’s say that for this case of , we know something about . At that point, we can end the chain of dependencies, and we end up with a finite chain of dependencies like so:
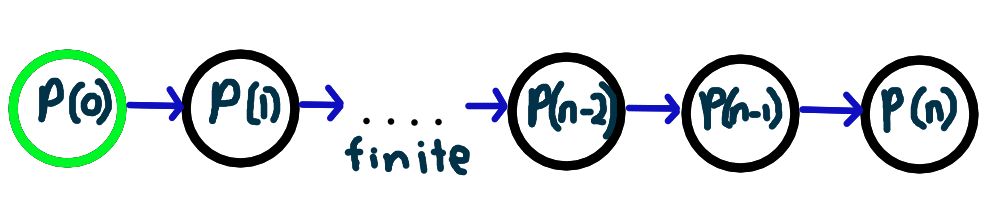
This chain of dependencies is just another way of looking at the conditions needed for the weak induction principle:
- holds (this is the start of the chain in green)
- (these are the blue arrows in the dependency chain)
Working from the beginning, we can work out the logical steps on how mathematical induction works:
- To know if holds, it would be nice to know if holds
- To know if holds, it would be nice to know if holds
- … (and so on, a finite number of steps)
- To know if holds, it would be nice to know if holds
- To know if holds, it would be nice to know if holds
- Hey, we know that holds! That’s easy.
- Since we know that holds, holds too
- To know if holds, it would be nice to know if holds
- Since we know that holds, holds too
- To know if holds, it would be nice to know if holds
- … (and so on, a finite number of steps)
- … (and so on, a finite number of steps)
- Since we know that holds, holds too
- To know if holds, it would be nice to know if holds
- Since we know that holds, holds too.
- We solved exactly what we wanted in the first place!
The chain of dependencies being finite and starting from a point that we know about is important here. If this chain never ended up at something we knew how to do, we wouldn’t be able to have a place of truth to start from. If the chain was actually infinite, we would never get back to the problem we started with. This is the point I want to really emphasize:
Mathematical induction is a method for reasoning about finite dependency structures 1
But why would we think that even depends on in the first place? That doesn’t actually have to be the case. can depend on a variety of other statements (even multiple other statements!), but as long as that dependency structure is finite, we can reason about it using induction. The dependency structures that come up in programming problems are natural to the problem, much more natural than trying to guess what the statement depends on. So let’s just hop into using induction in algorithms instead.
A simple example for induction in algorithms
I’ll first use an easy problem so that we don’t get too distracted by the difficulty of the problem itself and just focus on the dependency structure for induction.
Problem: Consider an non-empty array of numbers a, make a function array_sum(a) that returns the sum of all the elements in a.
Example: Let a = [2, 5, 2, 4, 6, 1, 5]. The sum of a is 2 + 5 + 2 + 4 + 6 + 1 + 5 = 25.
Some notation:
a[:m]is the subarray of a containing just the first m elementsa[i]is the (i+1)’th element ofa(the first element of the array isa[0]due to 0-indexing)
Most programmers can do this by writing a loop:
But what if we didn’t know how to write a loop, but we knew at least some basic properties of addition? In particular, we know
that if we somehow knew the sum of the first n-1 elements (array_sum(a[:n-1])), then we could get the sum array_sum(a[:n])
by just adding array_sum(a[:n-1]) and the nth element a[n-1] together. That is, we can start a dependency chain with
array_sum[:n] being dependent on array_sum[:n-1]. Similarly, array_sum[:n-1] can be solved if we knew array_sum(a[:n-2])
because we can just add the n-1’th element a[n-2] to array_sum(a[:n-2]), so array_sum[:n-1] is dependent on array_sum[:n-2].
This chain of logic can be continued until we get to a subarray of just size 1, a[:1]. Eventually reaching a subarray of size 1 is guaranteed
since n is finite (no infinite arrays allowed!) and we’re always decreasing the subarray size on each step.
We know the sum of the subarray a[:1], it’s just the single element a[0]. So we can stop the chain of dependencies there.
This gives us a dependency chain similar to that of the previous induction example:
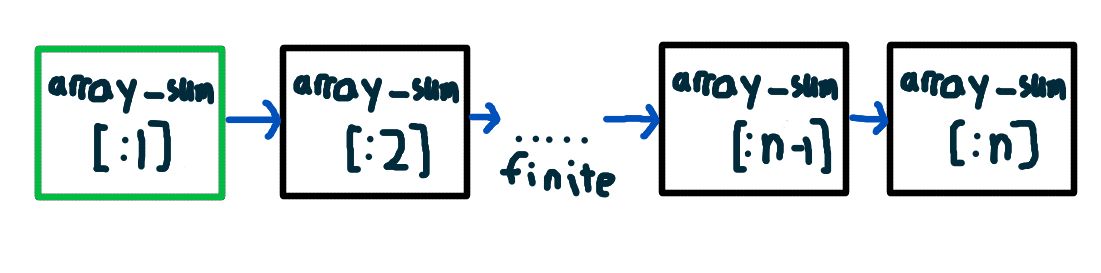
So for any non-empty array a, we can follow this chain of deductions:
- To calculate
array_sum(a[:n]), it would be nice to havearray_sum(a[:n-1])- To calculate
array_sum(a[:n-1]), it would be nice to havearray_sum(a[:n-2])- … (and so on, finite number of steps)
- To calculate
array_sum(a[:2]), it would be nice to havearray_sum(a[:1])- Hey, we can calculate
array_sum(a[:1]), that’s just a[0]!
- Hey, we can calculate
- Since we have
array_sum(a[:1]), we can now calculatearray_sum(a[:2])
- To calculate
- … (and so on, finite number of steps)
- … (and so on, finite number of steps)
- Since we have
array_sum(a[:n-2]), we can now calculatearray_sum(a[:n-1])
- To calculate
- Since we have
array_sum(a[:n-]), we can now calculatearray_sum(a[:n]) - We calculated what we wanted in the first place!
This structure also naturally gives us an alternative algorithm that’s just based on recursion. To calculate array_sum(a[:n]),
we call array_sum recursively on any dependency we don’t easily know, until we get to the easy case of just an array of 1 element:
Don’t actually write code like this for a programming interview though since it’s doing an array slice on each call. (If you do this, at least tell your interviewer that you just really like functional programming. If you then get the job, I look forward to getting a good reference from you). I just give it here as an example of a recursive algorithm naturally derived from inductive reasoning. In this case, it may seem a little silly because the problem was simple enough to solve through a loop. But let’s try to do a problem where the loop solution is not so immediately obvious.
A dependency structure that’s not just a line
Let’s consider this problem, which is slightly more complex than adding all the elements of an array.
Problem: Consider an non-empty array of positive numbers a and paths that start from the 0th index and end at the last (n-1’th) index.
Paths can be only constructed by going forward either 1 or 2 indices at each step. The path cost is the sum of the array elements visited. Make a
function min_skip_path(a) that returns the minimum possible path cost for the array a.
Example: Let a = [2, 5, 2, 4, 6, 1, 5]. One possible path is the one that visits indices [0, 2, 4, 6] for a path cost of 2 + 2 + 6 + 5 = 15.
However, the minimum path is actually the path that visits indices [0, 2, 3, 5, 6] for a path cost of 2 + 2 + 4 + 1 + 5 = 14. So
min_skip_path([2, 5, 2, 4, 6, 1, 5]) returns 14.
This problem seems kind of tricky to think about in the beginning, but there’s actually a way to do this with a simple loop as well! However, if you’re like me, the loop solution isn’t immediately obvious. Let’s instead try to stumble backwards onto a solution using inductive reasoning.
Let’s consider the min path we want to find. In that path, what was the step that finally got us
to the end, the nth element of a? It must have been a step that moved forward either 1 index or 2 indices. If that step moved forward 1 index,
then the last visited element was a[n-2] (the n-1’th element). Similarly if that step had moved forward 2 indices instead, then the last
visited element was a[n-3] (the n-2’th element). These are the only 2 options allowed, the min path for a[:n] must go through either one of those
elements.
So if we somehow knew what min_skip_path(a[:n-1]) (the cost of the min path that ends at the (n-1)’th element) and min_skip_path(a[:n-2])
(the cost of the min path that ends at the (n-2)’th element) were, then the value of min_skip_path(a[:n]) is straightforward to calculate.
You check which one of min_skip_path(a[:n-1]) or min_skip_path(a[:n-2]) is smaller, and then add a[n-1] (the cost of the nth element) to the
end of that path.
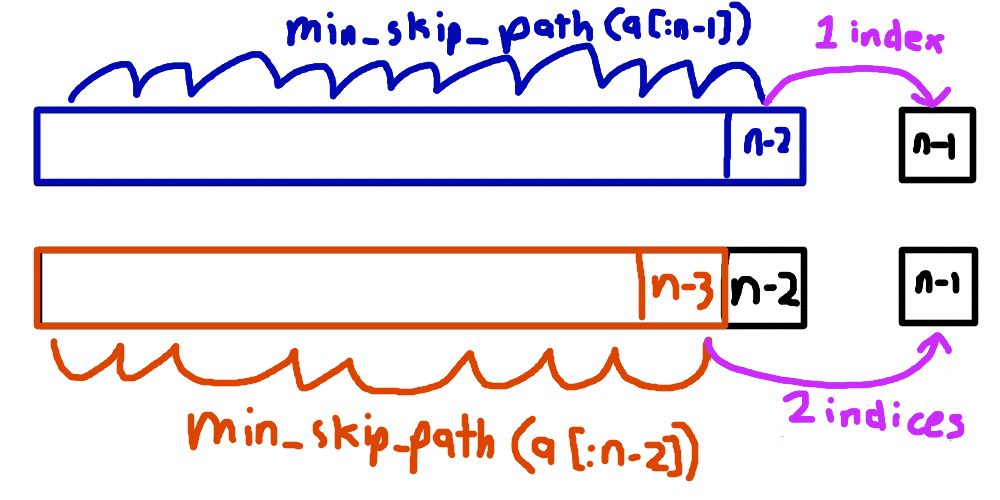
The only 2 options for min_skip_path(a[:n]) must include either min_skip_path(a[:n-1]) or min_skip_path(a[:n-2]). In fact, it must use the
smaller of the 2 options.
This logic gives us a dependency structure that starts to branch out like a binary tree, like so (I’m only writing the subarray to save space):
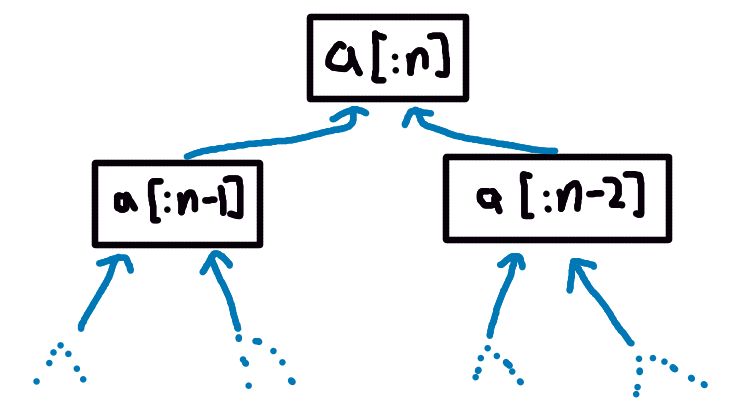
If we ever get to an array of just one element, the cost of the minimum path for that array is just that one element itself. Since n is finite and
any chain path in this tree dependencies is always from a subproblem is that’s smaller than it (either 1 element or
2 elements smaller), every path in this tree must eventually end up at an array with just one element a[:1] (assuming we don’t allow our algorithm to skip over the first
element with a 2 index jump, because that would just be silly).
Since all dependency paths in this dependency tree have to end at some point, we can apply the same principle of induction as we saw in
the example with a dependency chain. We end up having to start from multiple starting points and work back up the dependency tree
to get the answer for the original array min_skip_path(a[:n]).
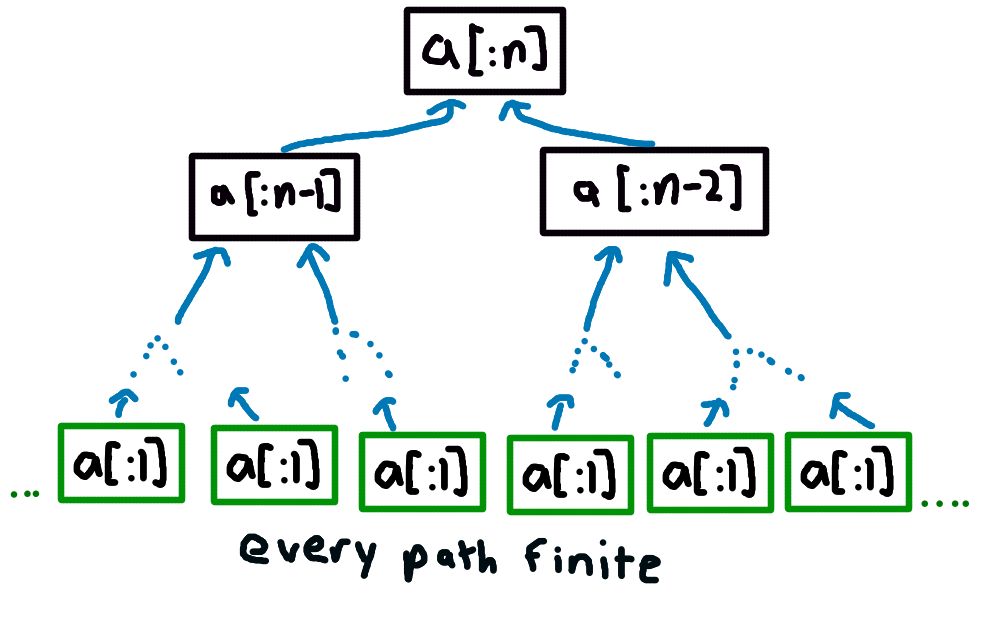
The overall logic looks like:
- To calculate
min_skip_path(a[:n]), it would be nice to havemin_skip_path(a[:n-1])andmin_skip_path(a[:n-2])- To calculate
min_skip_path(a[:n-1]), it would be nice to havemin_skip_path(a[:n-2])andmin_skip_path(a[:n-3])- (and so on, for a finite number of steps)
- To calculate
min_skip_path(a[:3]), it would be nice to havemin_skip_path([a:1])andmin_skip_path(a[:2])- To calculate
min_skip_path(a[:2]), it would be nice to havemin_skip_path([a:1])- Hey, we can easily calculate
min_skip_path([a:1])!
- Hey, we can easily calculate
- Since we have
min_skip_path([a:1]), we can calculatemin_skip_path(a[:2]) - Hey, we can easily calculate
min_skip_path([a:1])! - Since we have
min_skip_path([a:1])andmin_skip_path(a[:2]), we can calculatemin_skip_path(a[:3])
- To calculate
- (and so on, for a finite number of steps)
- Since we have
min_skip_path(a[:n-2])andmin_skip_path(a[:n-3]), we can calculatemin_skip_path(a[:n-1]) - To calculate
min_skip_path(a[:n-2]), it would be nice to havemin_skip_path(a[:n-3])andmin_skip_path(a[:n-4])- (and so on, for a finite number of steps)
- To calculate
min_skip_path(a[:3]), it would be nice to havemin_skip_path([a:1])andmin_skip_path(a[:2])- To calculate
min_skip_path(a[:2]), it would be nice to havemin_skip_path([a:1])- Hey, we can easily calculate
min_skip_path([a:1])!
- Hey, we can easily calculate
- Since we have
min_skip_path([a:1]), we can calculatemin_skip_path(a[:2]) - Hey, we can easily calculate
min_skip_path([a:1])! - Since we have
min_skip_path([a:1])andmin_skip_path(a[:2]), we can calculatemin_skip_path(a[:3])
- To calculate
- (and so on, for a finite number of steps)
- Since we have
min_skip_path(a[:n-3])andmin_skip_path(a[:n-4]), we can calculatemin_skip_path(a[:n-2])
- To calculate
- Since we have
min_skip_path(a[:n-1])andmin_skip_path(a[:n-2]), we can calculatemin_skip_path(a[:n]) - We got the answer to our original problem!
From this dependency tree, we can naturally change this into an algorithm that calculates dependencies by recursive calls until we get to a case we can trivially calculate, an array of just 1 element:
Bonus:
From the dependency tree, one might notice that there’s quite a bit of repeated calculation. For example,
min_skip_path(a[:n-2]) is calculated at least twice in the dependency tree as written. We could save some unnecessary work by
saving the result of a calculation to be able to reuse them if that same calculation appears again. This trick is called
“memoization” or “dynamic programming” and would make this algorithm run much faster than just naively calculating every
dependency. In fact, that’s the way you can derive the loop solution I alluded to in the beginning of the section.
But that’s a distraction to my point here and it’s a topic for another day. I just want to highlight the
process of taking a problem, thinking about a way to express solving it with a dependency structure, and using recursion/induction
to come up with an algorithm.
Wrapping up
In this post, I wanted to show how to think of induction in a way that’s more generally applicable particularly for programmers. That is, instead of thinking of induction as a way to solve problems just about natural numbers by chaining statements upwards, we can use induction to reason about any dependency structure that is finite. It turns out that many programming problems can naturally be expressed into a finite dependency structure which gives a natural recursive algorithm to solve the problem.
In this post, we just talked about problems that involve arrays, but these induction principles also apply to problems to other data structures , such as linked lists, grids (2D arrays), and even trees. In fact, in many cases, recursion is a much easier way to think about the problem than any iterative algorithm (e.g. anything related to trees and search paths). Perhaps I’ll provide some examples of this in another post.
As always, if you have any questions (about this, or just anything you’re curious about), comments, or just want to say hi, you can email me at me@lalaheadpats.com.
Footnotes
-
The entire dependency structure doesn’t have to necessarily be finite for induction to work. The necessary condition is that just every dependency path is finite, even if the structure itself is infinite in size. If property of all dependency paths being finite is true, then the relation defined by the dependency structure is called “well-founded”. But in typical programming problems, this distinction doesn’t really come up. So I’ll just hand wave a bit to avoid having to explain a little of set theory along the way. But if you’re interested in that, and the concept of induction on infinite sets bigger than the natural numbers, check out “Transfinite Induction” ↩